
手机版 欢迎访问某某自媒体运营网(www.baidu.com)网站

在神经网络的训练中,有两个重要的概念,
简单来说损失函数是评价指标,优化函数是网络的优化策略
为了更高效的优化网络结构(损失函数最小),我们需要最恰当的优化函数来优化网络,常用的优化函数有: SGD、BGD、MBGD、Momentum、NAG、Adagrad、Adadelta,RMSprop、Adam,其中:
SGD随机梯度下降参数更新原则:
单条数据就可对参数进行一次更新。每个epoch参数更新M(样本数)次,
这里的随机是指每次选取哪个样本是随机的,每个epoch样本更新的顺序是随机的
注:离线学习就是使用随机梯度下降算法对模型进行更新,对于每一个样本都计算一次梯度并更新模型
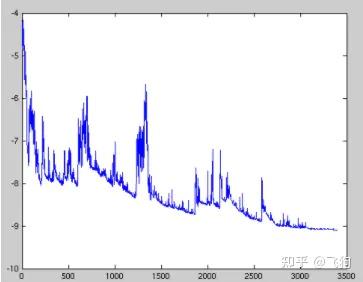
随机梯度下降算法,每次训练少量数据,抽样偏差导致的参数收敛过程中震荡。
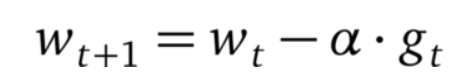
在随机梯度下降算法(SGD)中,优化器基于小批量估计梯度下降最快的方向,并朝该方向迈出一步。由于步长固定,因此 SGD 可能很快停滞在平稳区(plateaus)或者局部最小值上。SGD 每次更新时对每个样本进行梯度更新,对于很大的数据集来说,可能会有相似的样本,这样 BGD 在计算梯度时会出现冗余,而 SGD 一次只进行一次更新,就没有冗余,而且比较快,并且可以新增样本。
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad=evaluate_gradient(loss_function, example, params)
params=params - learning_rate * params_grad
看代码,可以看到区别,就是整体数据集是个循环,其中对每个样本进行一次参数更新。
缺点:但是 SGD 因为更新比较频繁,会造成 cost function 有严重的震荡。
BGD 可以收敛到局部极小值,当然 SGD 的震荡可能会跳到更好的局部极小值处。
当我们稍微减小 learning rate,SGD 和 BGD 的收敛性是一样的。
BGD批量梯度下降参数更新原则:每次将所有样本的梯度求和,然后根据梯度和对参数进行更新,
每个epoch参数更新1次。
梯度更新规则:11.5. 小批量随机梯度下降 - 动手学深度学习 2.0.0-beta1 documentation梯度更新规则:
MBGD 每一次利用一小批样本,即 n 个样本进行计算,本质上就是在每个batch内部使用BGD策略,在batch外部使用SGD策略。
注:MBGD优化器对每个batch内所有样本的梯度求均值,然后使用梯度的均值更新模型,因此使用MBGD优化器进行更新属于离线学习,同理BGD也属于离线学习
另一方面可以充分地利用深度学习库中高度优化的矩阵操作来进行更有效的梯度计算。
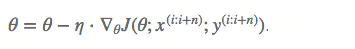
和 SGD 的区别是每一次循环不是作用于每个样本,而是具有 n 个样本的批次
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad=evaluate_gradient(loss_function, batch, params)
params=params - learning_rate * params_grad
超参数设定值:
n 一般取值在 50~256
缺点:不过 Mini-batch gradient descent 不能保证很好的收敛性,
有一种措施是先设定大一点的学习率,当两次迭代之间的变化低于某个阈值后,就减小 learning rate,不过这个阈值的设定需要提前写好,这样的话就不能够适应数据集的特点。
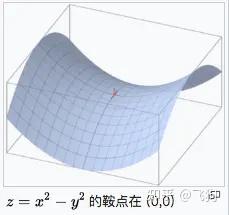
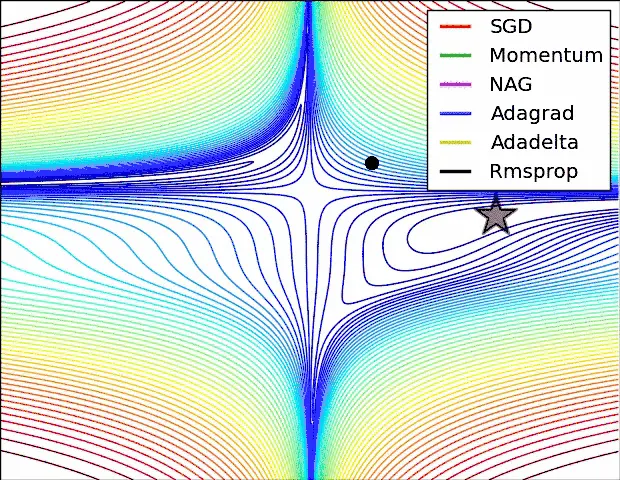
鞍点就是:一个光滑函数的鞍点邻域的曲线,曲面,或超曲面,都位于这点的切线的不同边。
例如这个二维图形,像个马鞍:在x-轴方向往上曲,在y-轴方向往下曲,鞍点就是(0,0)
引入物理“动量”的概念,累积速度,减少震荡,使参数更新的方向更稳定。
每次梯度更新都会带有前几次梯度方向的惯性,使梯度的变化更加平滑,这一点上类似一阶马尔科夫假设;Momentum梯度下降算法能够在一定程度上减小权重优化过程中的震荡问题。
引入动量的具体方式是:通过计算梯度的指数加权平均数来积累之前的动量,进而替代真正的梯度,Momentum的优化函数的权重更新公式如下:
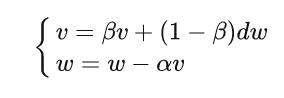
通过上述公式可以在,动量参数v本质上就是到目前为止所有历史梯度值的加权平均,距离越远,权重越小。
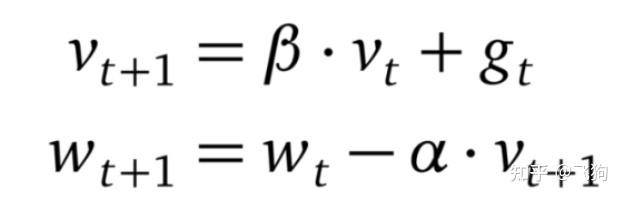
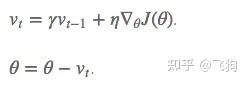
其中β<1。超参数设定值: 一般 γ取值 0.9 左右。
当带有动量时,SGD 会在连续下降的方向上加速(这就是该方法被称为「重球法」的原因)。
这种加速有助于模型逃脱平稳区,使其不易陷入局部极小值。
每个批次的数据含有抽样误差,导致梯度更新的方向波动较大。
如果我们引入物理动量的概念,给梯度下降的过程加入一定的“惯性”累积,就可以减少更新路径上的震荡,即每次更新的梯度由“历史多次梯度的累积方向”和“当次梯度”加权相加得到。
历史多次梯度的累积方向往往是从全局视角更正确的方向,这与“惯性”的物理概念很像,也是为何其起名为“Momentum”的原因。
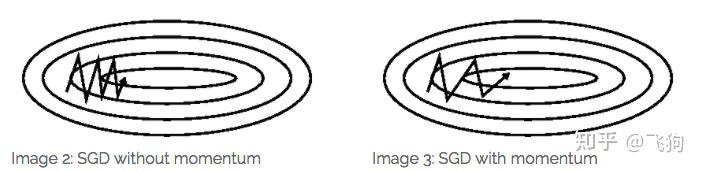
通过下面这张图片来理解动量法如何在优化过程中减少震荡
缺点:
这种情况相当于小球从山上滚下来时是在盲目地沿着坡滚,如果它能具备一些先知,例如快要上坡时,就知道需要减速了的话,适应性会更好。
通过下面这张图片来理解动量法如何在优化过程中减少震荡
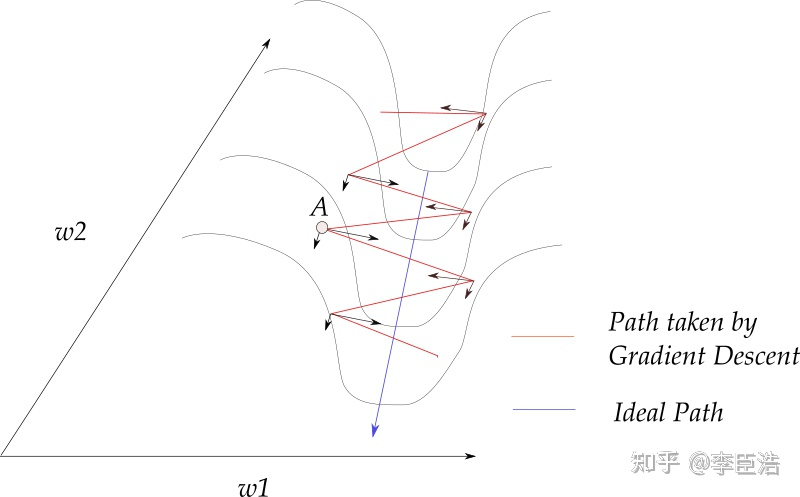
上图中每次权重更新的方向可以分解成W1方向上的w1分量和w2方向上的w2分量,
红线是传统的梯度下降算法权重更新的路径,在w1方向上会有较大的震荡
如果使用动量梯度下降算法,算法每次会累计之前的梯度的值。
以A点为例,在A点的动量是A点之前所有点的梯度的加权平均和,这样会很大程度抵消A点在w1上的分量,使A点在w2方向上获得较大的分量,从而使A点沿蓝色路径(理想路径)进行权重更新。
Nesterov Accelerated Gradient (牛顿动量梯度下降) 算法是Momentum算法的改进,原始公式如下:
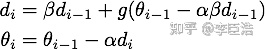
通过变换我们可以得到上边公式的等价形式:
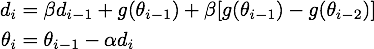
NAG算法会根据此次梯度(i-1)和上一次梯度(i-2)的差值对Momentum算法得到的梯度进行修正,
如果两次梯度的差值为正,证明梯度再增加,我们有理由相信下一个梯度会继续变大;
相反两次梯度的差值为负,我们有理由相信下一个梯度会继续变小。
如果说Momentum算法是用一阶指数平滑,那么NGA算法则是使用了二阶指数平滑;
Momentum算法类似用已得到的前一个梯度数据对当前梯度进行修正(类似一阶马尔科夫假设),
NGA算法类似用已得到的前两个梯度对当前梯度进行修正(类似二阶马尔科夫假设),
无疑后者得到的梯度更加准确,因此提高了算法的优化速度。
根据不同参数距离最优解的远近,动态调整学习率。
学习率逐渐下降,依据各参数变化大小调整学习率。
Adagrad算法能够在训练中自动的对学习率进行调整,对于出现频率较低参数采用较大的α更新(出现次数多表明参数波动较大,);相反,对于出现频率较高的参数采用较小的学习率更新,具体来说,每个参数的学习率反比于其历史梯度平方值总和的平方根。因此,Adagrad非常适合处理稀疏数据。
使用变量st来累加过去的梯度方差,如下所示:
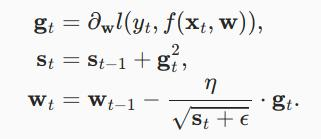
与之前一样,
η是学习率,
?是一个为维持数值稳定性而添加的常数,用来确保我们不会除以0。
最后,我们初始化s0=0。
特点:
缺点:
AdaGrad 是首批成功利用自适应学习率的方法之一。AdaGrad 基于平方梯度之和的倒数的平方根来缩放每个参数的学习率。该过程将稀疏梯度方向放大,以允许在这些方向上进行较大调整。结果是在具有稀疏特征的场景中,AdaGrad 能够更快地收敛。
通过调整学习率的实验可以发现:当某个参数的现值距离最优解较远时(表现为梯度的绝对值较大),我们期望参数更新的步长大一些,以便更快收敛到最优解。当某个参数的现值距离最优解较近时(表现为梯度的绝对值较小),我们期望参数的更新步长小一些,以便更精细的逼近最优解。类似于打高尔夫球,专业运动员第一杆开球时,通常会大力打一个远球,让球尽量落在洞口附近。当第二杆面对离洞口较近的球时,他会更轻柔而细致的推杆,避免将球打飞。与此类似,参数更新的步长应该随着优化过程逐渐减少,减少的程度与当前梯度的大小有关。根据这个思想编写的优化算法称为“AdaGrad”,Ada是Adaptive的缩写,表示“适应环境而变化”的意思。RMSProp是在AdaGrad基础上的改进,学习率随着梯度变化而适应,解决AdaGrad学习率急剧下降的问题。
Adagrad 的优点是减少了学习率的手动调节
超参数设定值:
一般 就取 0.01。
缺点:
它的缺点是分母会不断积累,这样学习率就会收缩并最终会变得非常小。
RMSprop解决的问题:解决Adagrad分母会不断积累,这样学习率就会收缩并最终会变得非常小的问题。
算法描述
RMSprop算法并没有被正式的发表,而是Geoff Hinton在他的课程中提及。
RMSprop是一种十分高效的算法,可以看作是对AdaGrad算法的改进,对历史的梯度信息使用decaying average的方式进行累计,在学习速率的处理上不再像AdaGrad那么激进。
RMSprop参数更新原则:RMSprop在Adagrad算法的基础上对 进行了一阶指数平滑处理
RMSprop算法的公式如下:
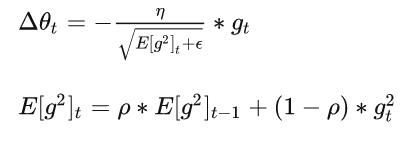
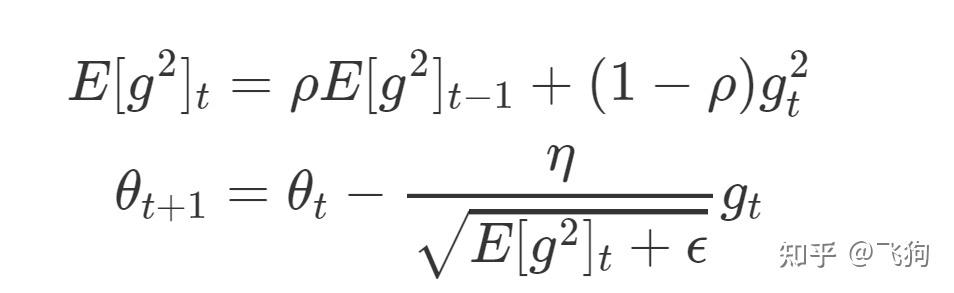
我们可以使用均方根(RMS)公式简化上述过程:
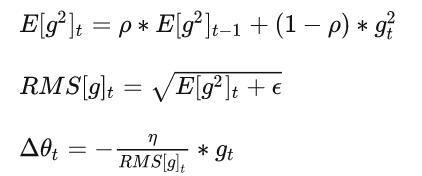
RMSprop 是一个未发布的优化器,但在最近几年中已被过度使用。
其理念类似于 AdaGrad,但是梯度的重新缩放不太积极:用平方梯度的移动均值替代平方梯度的总和。
RMSprop 通常与动量一起使用,可以理解为 Rprop 对小批量设置的适应。
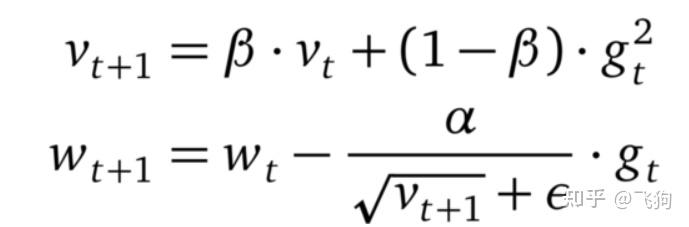
Adam 和 RMSprop(或 AdaGrad)之间一个主要区别是对瞬时估计 m 和 v 的零偏差进行了矫正。Adam 以少量超参数微调就能获得良好的性能著称。
RMSprop也可以和传统的momentum方法结合,但是Hinton表示这样做的帮助不是很大(相对于其对传统SGD的帮助而言),具体的原因需要更多的研究。
当然如果和Nesterov momentum结合能够有更好的效果
特点:
PyTorch实现
RMSprop - PyTorch 1.13 documentationclass torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)

weight_decay:
权重衰减率,正则化系数
momentum:
动量系数p,继承上一步的方向权重,常用的值是[0.9,0.99,0.999]
centered:
在PyTorch实现中,有一个centered的标志,即是否使用centered版本的RMSprop。
centered版本的的RMSprop按照
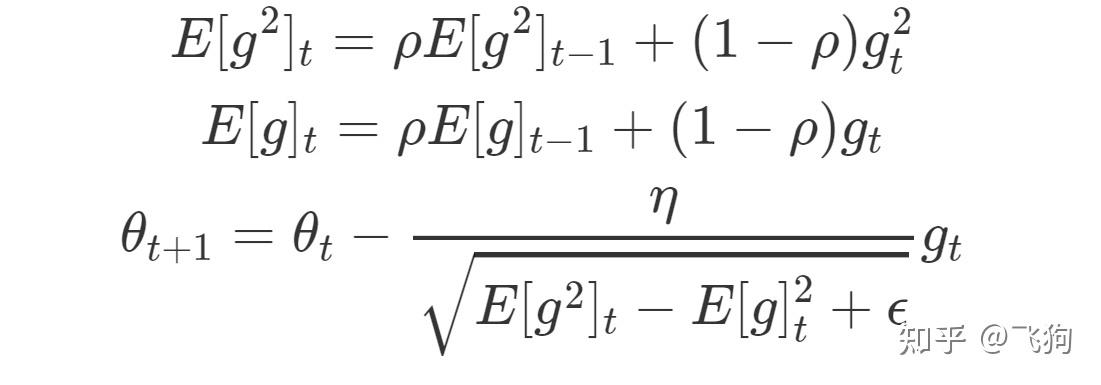
RMSprop优化器虽然可以对不同的权重参数自适应的改变学习率,但仍要指定超参数 ,
AdaDelta优化器对RMSProp算法进一步优化:
AdaDelta算法额外维护一个状态变量 ,并使用
代替 RMSprop 中的学习率参数
,使AdaDelta优化器不需要指定超参数
简而言之,Adadelta使用两个状态变量,
st用于存储梯度二阶导数的泄露平均值,
Δxt用于存储模型本身中参数变化二阶导数的泄露平均值。
AdaDelta 的计算公式如下:
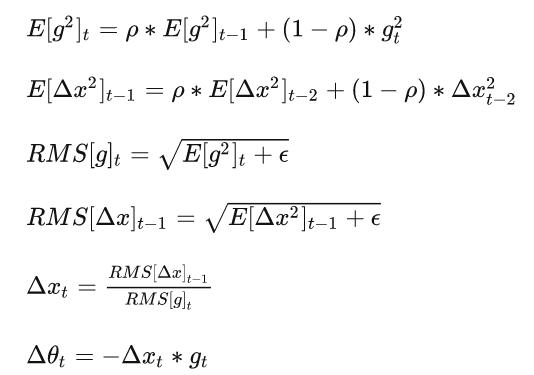
gt、的初始值都为0,这就导致算法开始时得到的
和
都很小,因此,在实际工作中,我们往往会:
和
中的 t 表示 t 次方,因为
和
小于1,
因此 t 越大,两个式子中的分母越接近于1
当t很小时,分母较小,因此可以放大 和
,从而解决上述问题
特点:
由于动量和自适应学习率两个优化思路是正交的,因此可以将两个思路结合起来,这就是当前广泛应用的Adma算法。
https://arxiv.org/pdf/1412.6980.pdfAdma吸收了Adagrad(自适应学习率的梯度下降算法)和动量梯度下降算法的优点,既能适应稀疏梯度(即自然语言和计算机视觉问题),又能缓解梯度震荡的问题
11.10. Adam算法 - 动手学深度学习 2.0.0-beta1 documentationAdam算法的关键组成部分之一是:它使用指数加权移动平均值来估算梯度的动量和二次矩,
即它使用状态变量
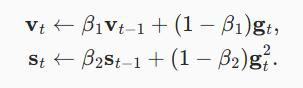
这里β1和β2是非负加权参数。 常将它们设置为β1=0.9和β2=0.999。
也就是说,方差估计的移动远远慢于动量估计的移动。
注意,如果我们初始化v0=s0=0,就会获得一个相当大的初始偏差。
我们可以通过使用
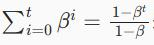
来解决这个问题。
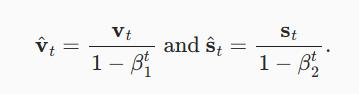
下一步的方向由梯度的移动平均值决定,步长大小由全局步长大小设置上限。
有了正确的估计,我们现在可以写出更新方程。
首先,我们以类似于 RMSprop,Adam 对梯度的每个维度进行重新缩放。
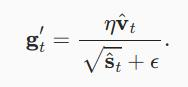
与RMSProp不同,我们的更新使用动量v^t而不是梯度本身。
此外,由于使用
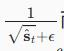
而不是
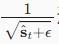
进行缩放,两者会略有差异。
前者在实践中效果略好一些,因此与RMSProp算法有所区分。
通常,我们选择?=10?6,这是为了在数值稳定性和逼真度之间取得良好的平衡。
梯度更新规则:
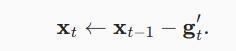
超参数设定值: 建议 β1 = 0.9,β2 = 0.999,? = 10e?8
实践表明,Adam 比其他适应性学习方法效果要好。
pytorch实现
https://pytorch.org/docs/stable/generated/torch.optim.Adam.htmlCLAS
Storch.optim.Adam(params,lr=0.001,betas=(0.9,0.999),eps=1e-08,weight_decay=0,amsgrad=False,*,foreach=None,maximize=False,capturable=False,differentiable=False,fused=False)

Parameters:
Adam算法也存在一些问题:
即使在凸环境下,当st的二次矩估计值爆炸时,它可能无法收敛。
https://proceedings.neurips.cc/paper/2018/file/90365351ccc7437a1309dc64e4db32a3-Paper.pdf为st提出了的改进更新和参数初始化。
论文中建议我们重写Adam算法更新如下:
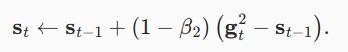
每当gt2具有值很大的变量或更新很稀疏时,st可能会太快地“忘记”过去的值。
一个有效的解决方法是将g^2?S(t?1)替换为gt^2⊙sgn?(gt^2?S(t?1))。
这就是Yogi更新,现在更新的规模不再取决于偏差的量。
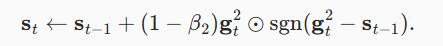

Loshchilov 和 Hutter 在自适应梯度方法中确定了 L2 正则化和权重下降的不等式,并假设这种不等式限制了 Adam 的性能。然后,他们提出将权重衰减与学习率解耦。
实验结果表明 AdamW 比 Adam(利用动量缩小与 SGD 的差距)有更好的泛化性能,并且对于 AdamW 而言,最优超参数的范围更广。
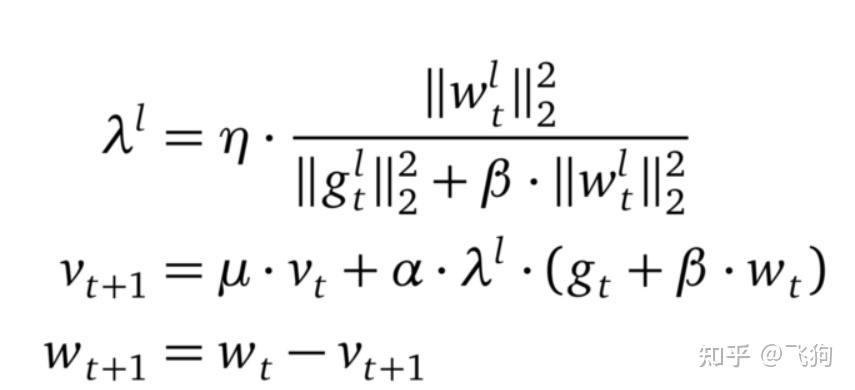
LARS 是 SGD 的有动量扩展,可以适应每层的学习率。
LARS 最近在研究界引起了关注。
这是由于可用数据的稳定增长,机器学习的分布式训练也变得越来越流行。
这使得批处理大小开始增长,但又会导致训练变得不稳定。
有研究者(Yang et al)认为这些不稳定性源于某些层的梯度标准和权重标准之间的不平衡。
因此他们提出了一种优化器,该优化器基于「信任」参数η<1 和该层梯度的反范数来重新调整每层的学习率。
增加model随机性:
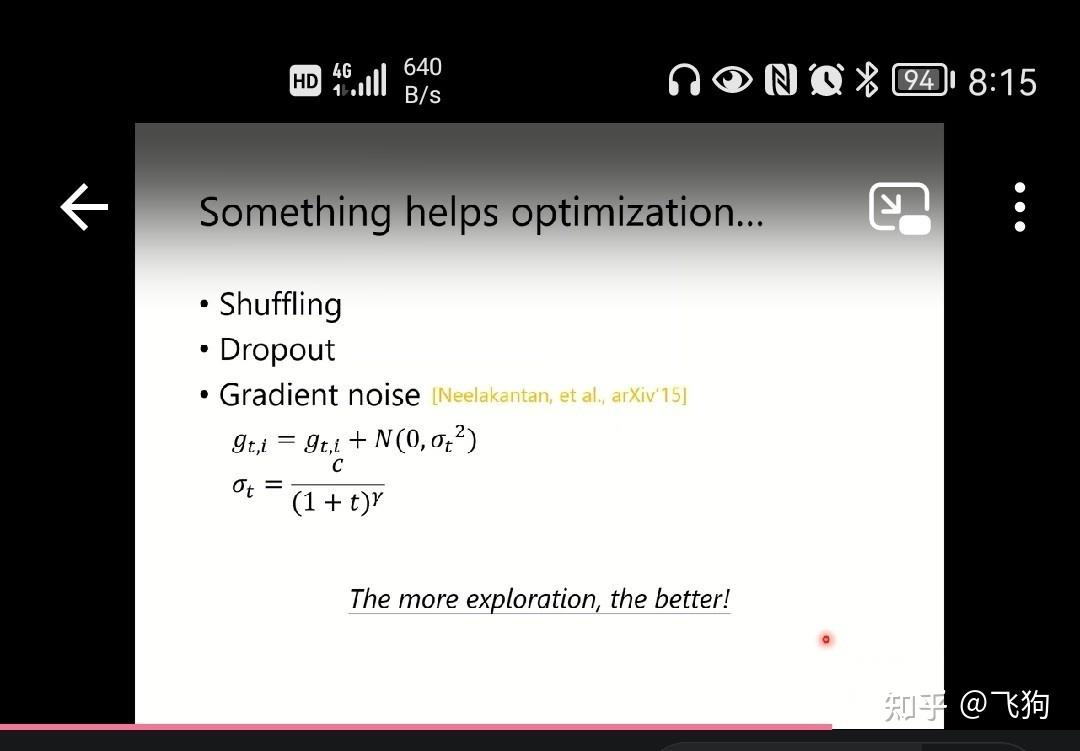
something helps:
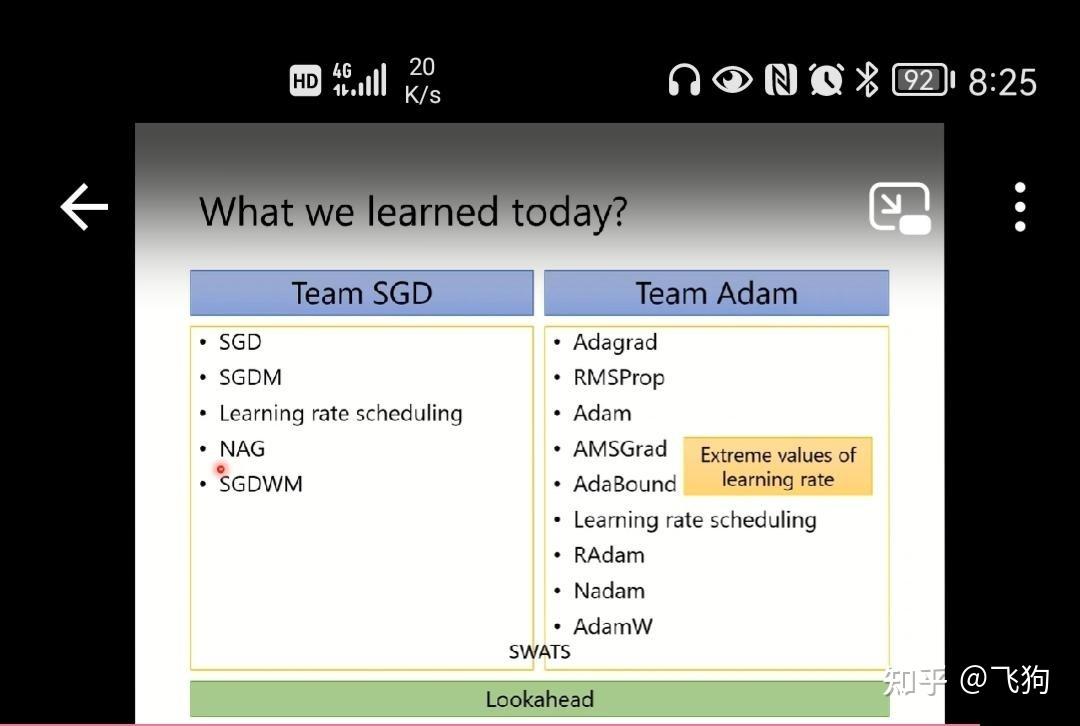
from 李宏毅2021机器学习课程:


| SGD大类 | Adam大类 |
|---|---|
| SGD | Adagrad |
| SGDM | RMSProp |
| Learning rate scheduling | Adam |
| NAG | AMSGrad(LR有额外的参数) |
| SGDWM | AdaBound(LR有额外的参数) |
| Learning rate scheduling | |
| RAdam | |
| Nadam | |
| AdamW | |
| SWATS | SWATS |
| Lookahead | Lookahead |
| SGDM | Adam |
|---|---|
| slow | fast |
| better convergence | possibly non-convergence |
| stable | unstable |
| smaller generalization gap | larger generalization gap |
| SGDM | Adam |
|---|---|
| CV | NLP |
| -img classification | -QA |
| -segmentation | -machine translation |
| -object detection | -summary |
| Speech synthesis | |
| GAN | |
| Reinforcement learning |
from 李宏毅2021机器学习课程:


如上所述,为机器学习问题选择合适的优化器可能非常困难。更具体地说,没有万能的解决方案,只能根据特定问题选择合适的优化器。但在选择优化其之前应该问自己以下 3 个问题:
如果您使用的是新型机器学习方法,那么可能存在一篇或多篇涵盖类似问题或处理了类似数据的优秀论文。通常,论文作者会进行广泛的交叉验证,并且给出最成功的配置。读者可以尝试理解他们选择那些优化器的原因。
例如:假设你想训练生成对抗网络(GAN),以对一组图像执行超分辨率。经过一番研究后,你偶然发现了一篇论文[12],研究人员使用 Adam 优化器解决了完全相同的问题。威尔逊等人[2]认为训练 GAN 并不应该重点关注优化问题,并且 Adam 可能非常适合这种情况。所以在这种情况下,Adam 是不错的优化器选择。
此外,你的数据集中是否存在可以发挥某些优化器优势的特性?如果是这样,则需要考虑优化器的选择问题。
下表 1 概述了几种优化器的优缺点。读者可以尝试找到与数据集特征、训练设置和项目目标相匹配的优化器。某些优化器在具有稀疏特征的数据上表现出色,而有一些将模型应用于先前未见过的数据时可能会表现更好。一些优化器在大批处理量下可以很好地工作,而另一些优化器会在泛化不佳的情况下收敛到极小的最小值。
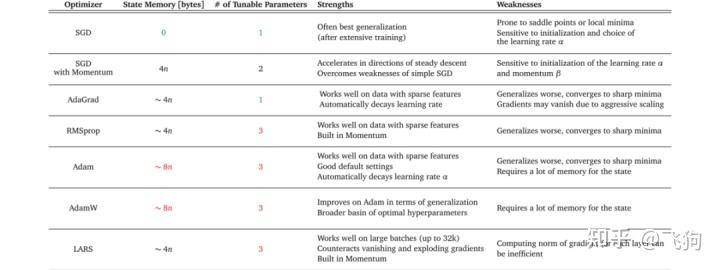
举例而言:如果你需要将用户给出的反馈分类成正面和负面反馈,考虑使用词袋模型(bag-of-words)作为机器学习模型的输入特征。由于这些特征可能非常稀疏,所以决定采用自适应梯度方法。但是具体选择哪一种优化器呢?参考上表 1,你会发现 AdaGrad 具有自适应梯度方法中最少的可调参数。在项目时间有限的情况下,可能就会选择 AdaGrad 作为优化器。
最后需要考虑的问题:该项目有哪些资源?项目可用资源也会影响优化器的选择。计算限制或内存限制以及项目时间范围都会影响优化器的选择范围。
如上表 1 所示,可以看到每个优化器有不同的内存要求和可调参数数量。此信息可以帮助你估计项目设置是否可以支持优化器的所需资源。
举例而言:你正在业余时间进行一个项目,想在家用计算机的图像数据集上训练一个自监督的模型(如 SimCLR)。对于 SimCLR 之类的模型,性能会随着批处理大小的增加而提高。因此你想尽可能多地节省内存,以便进行大批量的训练。选择没有动量的简单随机梯度下降作为优化器,因为与其他优化器相比,它需要最少的额外内存来存储状态。
如果数据是稀疏的,就用自适用方法,即 Adagrad, Adadelta, RMSprop, Adam。
RMSprop, Adadelta, Adam 在很多情况下的效果是相似的。
Adam 就是在 RMSprop 的基础上加了 bias-correction 和 momentum,
随着梯度变的稀疏,Adam 比 RMSprop 效果会好。
整体来讲,Adam 是最好的选择。
很多论文里都会用 SGD,没有 momentum 等。SGD 虽然能达到极小值,但是比其它算法用的时间长,而且可能会被困在鞍点。
如果需要更快的收敛,或者是训练更深更复杂的神经网络,需要用一种自适应的算法。
使用什么优化器_优化器怎么选?一文教你选择适合不同ML项目的优化器_慕容隽的博客-CSDN博客如何选择优化器 optimizer_aliceyangxi1987的博客-CSDN博客Copyright © 2002-2022 首页-雷神娱乐电商新闻发布站 版权所有






 阿里斥资46.6亿"拿
阿里斥资46.6亿"拿 心痛!各大电商平台竞相下调iPhone售
心痛!各大电商平台竞相下调iPhone售